roam-pic.com
An AI tour guide assistant that empowers users to learn about the world around them!
ROAM is an AI tour guide assistant that empowers users to learn about the world around them. The platform enables users to upload an image of a landmark, and receive instant information about its history and significance. From active travelers to passive wanderers, our mission is to empower individuals to learn in a simple and intuitive way that will help foster understanding, empathy, and global awareness!
Mission Statement

Our world is becoming increasingly interconnected as technology continues to develop and improve. It is our collective job to continue teaching and learning about those with different backgrounds.
When traveling to or exploring a new destination, it is often difficult to learn about the culture, history, or significance behind interesting landmarks without the assistance of a tour guide or local expert. By combining image detection with retrieval augmented generation, ROAM brings the knowledge and charisma of local historians to the palms of travelers’ hands.
With image detection, users will first be able to confidently identify what surrounds them. Incorporating retrieval augmented generation then provides succinct summaries about historical significance and other relevant information for the user to learn from. This knowledge will help build stronger relationships across disparate communities and promote inclusivity.
Product + Features
- Interactive and mobile-friendly website
- Geolocating
- Landmark Identification
- Landmark Identification Confidence
- Interesting information about the identified landmark

Demo
High Level System Architecture
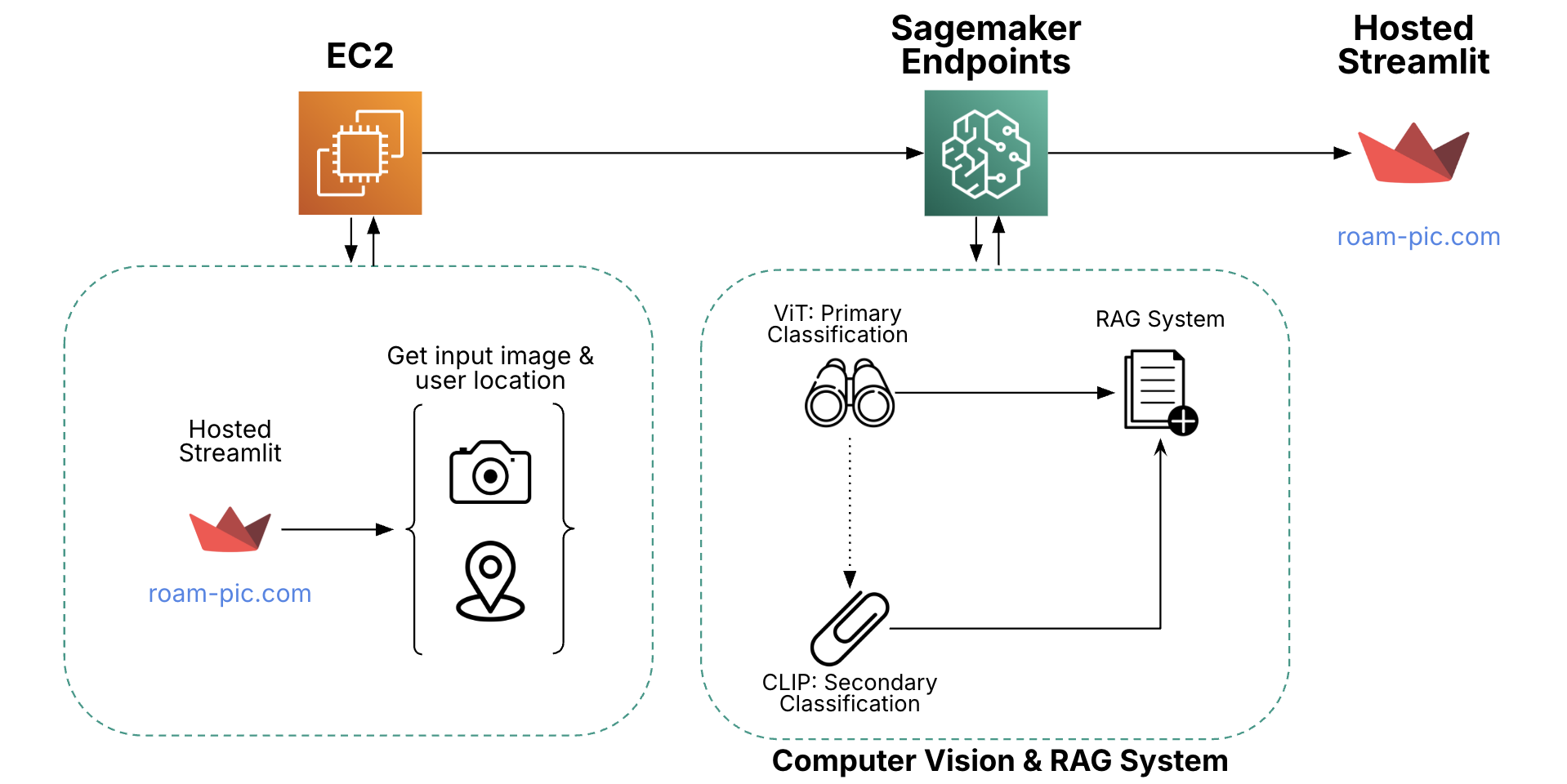
ROAM’s architecture is fully deployed on AWS EC2 and Sagemaker Endpoints. The front end application is hosted on a secure domain (roam-pic.com), which is ran on an EC2 instance. Using a secure domain allows for users to access Streamlit safely on their phone via web-access and allows access to camera and location information. When users take a photo of a landmark, the photo is sent to our AWS Sagemaker endpoints, which include two computer vision models for landmark detection and a RAG model for historical retrieval. This is then shown back to the user on Streamlit.
About the Data

For landmark detection, we are using the Google Landmarks v2 dataset. It was filtered down from ~4.2 million to ~1.6 million images by researchers at Google. With over 81 thousand landmarks, this made the data much more suitable for training a high precision landmark identification model. Still, several instances remained where the main object in the image was not aligned with the image’s label.
To programmatically filter out these noisy images, a visual question answering model called BLIP is used. For every image in each class (landmark), BLIP identifies the main object in the image. The frequency of each unique BLIP label for each class is counted and only the images within a class with the most frequent BLIP label are kept.
For the RAG pipeline, we used primarily two data sources: UNESCO and Wikipedia. The UNESCO dataset includes over 1,000 landmarks across 168 countries and is highly regulated, with strict submission guidelines ensuring data quality. To enrich this, we dynamically append the top two Wikipedia entries for the identified landmark using LangChain’s Wikipedia API. These entries are only added on demand—when a user queries the app—to keep the RAG database lightweight and retrieval times fast.
ML Architecture
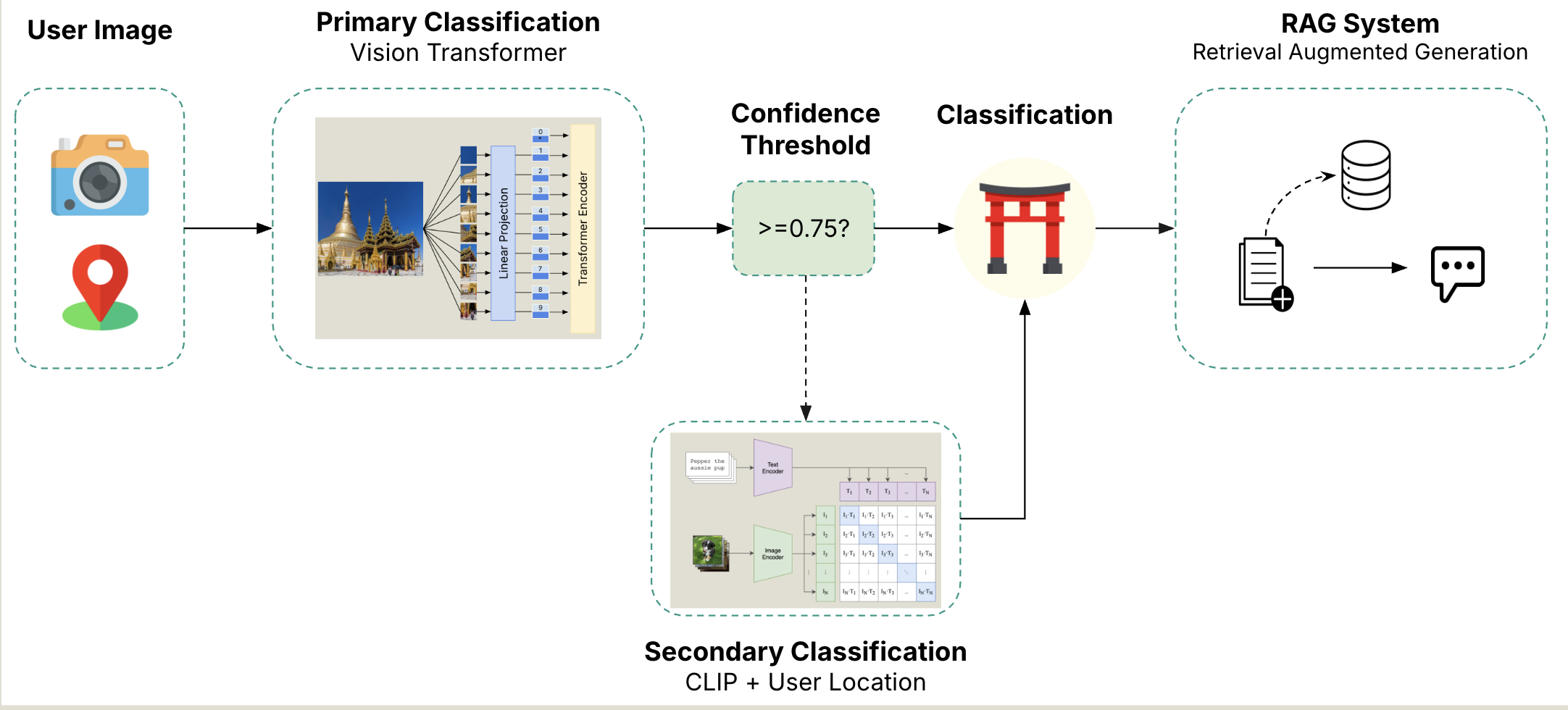
Let’s take a quick look at the Machine Learning Architecture. The process starts with the user provided image and location coordinates. The image is then passed to our Primary Classification model - we fined tuned a Vision Transformer from Google, using the landmark dataset described above. The finetuned model takes in the image, vectorizes it and breaks it up into sixteen patches, where a CLS token is included as well. The CLS token will contain the aggregated contextual representation of the entire image. After passing through the Vision Transformer, it then gets passed to a dense neural network containing one hidden layer and 200 neurons. Finally, a softmax activation function is applied, providing a probability distribution over all of the classes. The highest probability class is then compared against our confidence threshold - if the probability is below the threshold, the image will get passed to the Secondary Image Classification to try again.
For our secondary classification model, we are using CLIP from OpenAI in combination with AWS location services. CLIP is a neural net model that is trained on image and text pairs. The advantage of this model is that it can be used for zero-shot prediction where it is predicting classes it wasn’t directly trained on. By using the user’s location to narrow down landmarks CLIP could help us generalize to lesser known landmarks not seen by the first vision transformer. If the probability is above the threshold, the class label is displayed back to the user, and that label is used as the input to the RAG system to generate the landmark information to the user.
RAG Pipeline
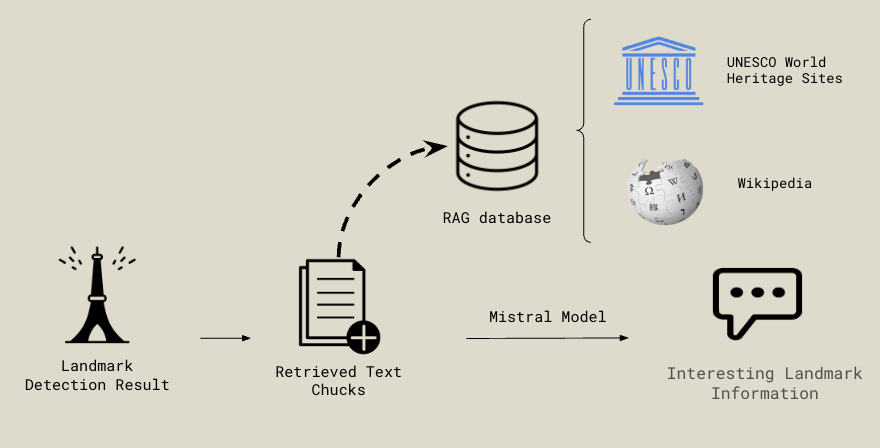
Once the vision model identifies the landmark from the user-provided image, the RAG pipeline retrieves relevant information to simulate an interactive tour guide experience. Using a custom prompt that includes the landmark and any additional user-provided details, the system queries a RAG database containing curated data from UNESCO World Heritage Sites and relevant Wikipedia entries.
The retrieved content from UNESCO and/or Wikipedia is then passed, along with the prompt, into the Mistral model’s context window. This generates engaging, tour guide-style responses tailored to the identified landmark.
Meet the Team

Samuel Greenberg
New York, NY

Yoni Nackash
New York, NY

Nicholas Lin
Boston, MA

Alice Lu
Orlando, FL

Hadi Hafezi
Irvine, CA